
Hi, All
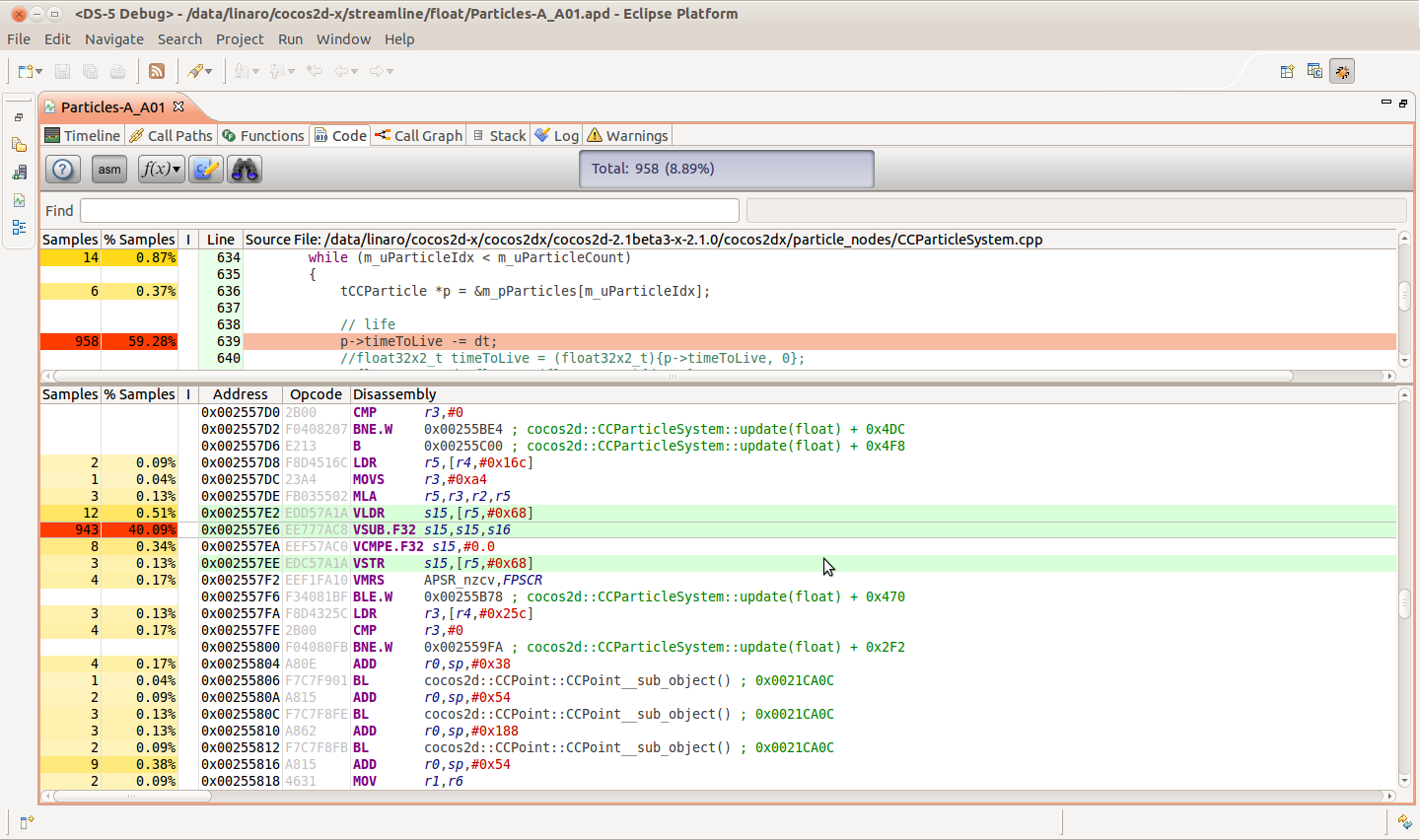
The attachment file is analysed by the streamline tool. How to do you think about the vsub.f32 hot spot there? Is there any way we can improve that?
{kind=link}

On 13 May 2013 13:52, YongQin Liu yongqin.liu@linaro.org wrote:
Hi, All
The attachment file is analysed by the streamline tool. How to do you think about the vsub.f32 hot spot there? Is there any way we can improve that?
It looks like there is a data dependency on the preceding load, it might be worth looking into prefetching the data, either manually or maybe try -fprefetch-loop-arrays?
-- Will Newton Toolchain Working Group, Linaro

On 14 May 2013 13:23, Will Newton will.newton@linaro.org wrote:
It looks like there is a data dependency on the preceding load, it might be worth looking into prefetching the data, either manually or maybe try -fprefetch-loop-arrays?
I agree with Matt on needing more info, but I also agree with Will that a pre-fetch could speed things up.
The beginning of the block is a few instructions up, and the address of the VLDR is computed by almost all instructions in the block, in chain, I'm assuming (without evidence) that it's the VLDR itself who is taking all that time to release S15 for VSUB.
Furthermore, the VLDR was hit 100x less than the VSUB, hinting that it's not waiting for too long waiting for anything, so the instructions before it calculating the offset are pretty much streamlined, another hint that it's the VLDR itself who is taking that long.
cheers, --renato
Hi, All
Thanks for all of your analysis.
The related information is as following:
- What is your source code?
It's the "void CCParticleSystem::update(float dt)" method of the attached CCParticleSystem.cpp file.
- How did you compile your source code?
I Compiled it with the android-ndk-r8d with the attached build_native.sh script. Also I set it to use armeabi-v7a and neon. but the neon should have no affects because there is no source using the neon features.
- What compiler did you use?
I use the default compiler of android-ndk-r8d, it should be arm-linux-androideabi-4.6
- What platform are you testing on?
The device I am testing on is an SP8810 device. here is the content of the cpuinfo
root@android:/ # cat /proc/cpuinfo
Processor : ARMv7 Processor rev 1 (v7l) BogoMIPS : 1024.00 Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3 CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x0 CPU part : 0xc05 CPU revision : 1
Hardware : SP8810 Revision : 0000 Serial : 0000000000000000 root@android:/ #
- Is there anyway you can generate a smaller test case?
Sorry, not able to that now.
For the "-fprefetch-loop-arrays", I enabled it by appending option "-O3 -fprefetch-loop-arrays", but there seems no improvement.
Thanks, Yongqin Liu
On 14 May 2013 22:03, Renato Golin renato.golin@linaro.org wrote:
On 14 May 2013 13:23, Will Newton will.newton@linaro.org wrote:
It looks like there is a data dependency on the preceding load, it might be worth looking into prefetching the data, either manually or maybe try -fprefetch-loop-arrays?
I agree with Matt on needing more info, but I also agree with Will that a pre-fetch could speed things up.
The beginning of the block is a few instructions up, and the address of the VLDR is computed by almost all instructions in the block, in chain, I'm assuming (without evidence) that it's the VLDR itself who is taking all that time to release S15 for VSUB.
Furthermore, the VLDR was hit 100x less than the VSUB, hinting that it's not waiting for too long waiting for anything, so the instructions before it calculating the offset are pretty much streamlined, another hint that it's the VLDR itself who is taking that long.
cheers, --renato
On 17 May 2013 08:18, YongQin Liu yongqin.liu@linaro.org wrote:
I Compiled it with the android-ndk-r8d with the attached build_native.sh script.
That's a gcc 4.7 right?
- What platform are you testing on?
The device I am testing on is an SP8810 device. here is the content of the cpuinfo
I believe that's a Cortex-A5.
root@android:/ # cat /proc/cpuinfo
Processor : ARMv7 Processor rev 1 (v7l)
<rant>Why don't we print full information like Intel?</rant>
For the "-fprefetch-loop-arrays",
I enabled it by appending option "-O3 -fprefetch-loop-arrays", but there seems no improvement.
It's possible that tCCParticle is too complex for the compiler to prefetch, possibly bigger than a cache line?
If you can change the source code, try to move the fist line of that loop to inside the loop, after the last use of p, saving it into a hoisted variable, initialized with the first iteration.
tCCParticle *p = &m_pParticles[m_uParticleIdx]; while (m_uParticleIdx < m_uParticleCount) { // life p->timeToLive -= dt; ... *p = &m_pParticles[m_uParticleIdx]; ... ++m_uParticleIdx; }
Not that you should leave the source code like that, but it'll give as a clue whether the load is really the problem here.
cheers, --renato

On 17 May 2013 13:30, Renato Golin renato.golin@linaro.org wrote:
On 17 May 2013 08:18, YongQin Liu yongqin.liu@linaro.org wrote:
- What platform are you testing on?
The device I am testing on is an SP8810 device. here is the content of the cpuinfo
I believe that's a Cortex-A5.
root@android:/ # cat /proc/cpuinfo Processor : ARMv7 Processor rev 1 (v7l)
<rant>Why don't we print full information like Intel?</rant>
The part you snipped:
CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x0 CPU part : 0xc05 CPU revision : 1
That says Cortex-A5 r0p1 loud and clear. What info do you think is missing?

On 17 May 2013 14:03, Mans Rullgard mans.rullgard@linaro.org wrote:
On 17 May 2013 13:30, Renato Golin renato.golin@linaro.org wrote:
<rant>Why don't we print full information like Intel?</rant>
The part you snipped:
CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x0 CPU part : 0xc05 CPU revision : 1
That says Cortex-A5 r0p1 loud and clear. What info do you think is missing?
The bit where it actually says "Cortex-A5" rather than requiring you to know or fish about in TRMs for part, variant and revision field meanings...
On Intel you get a human-readable vendor_id and model name.
thanks -- PMM
On 17 May 2013 14:26, Peter Maydell peter.maydell@linaro.org wrote:
On 17 May 2013 14:03, Mans Rullgard mans.rullgard@linaro.org wrote:
On 17 May 2013 13:30, Renato Golin renato.golin@linaro.org wrote:
<rant>Why don't we print full information like Intel?</rant>
The part you snipped:
CPU implementer : 0x41 CPU architecture: 7 CPU variant : 0x0 CPU part : 0xc05 CPU revision : 1
That says Cortex-A5 r0p1 loud and clear. What info do you think is missing?
The bit where it actually says "Cortex-A5" rather than requiring you to know or fish about in TRMs for part, variant and revision field meanings...
I suppose those who have a need for this information already know how to interpret those values. Translating the ARM IDs to model names would be rather trivial.
On Intel you get a human-readable vendor_id and model name.
That's because Intel CPUs have the friendly string encoded in the silicon and returned by the CPUID instruction. Also, you probably still have to go and look up exactly what an i7-3632QM (what I'm typing this on) is.
On 17 May 2013 14:45, Mans Rullgard mans.rullgard@linaro.org wrote:
I suppose those who have a need for this information already know how to interpret those values. Translating the ARM IDs to model names would be rather trivial.
Great! Do I hear someone volunteering to implement that in the Kernel? ;)
cheers, --renato

YongQin,
On 13/05/13 13:52, YongQin Liu wrote:
Hi, All
The attachment file is analysed by the streamline tool. How to do you think about the vsub.f32 hot spot there? Is there any way we can improve that?
Maybe - but you give very little information for us to help you.
We need more context - a screengrab is not enough:
* What is your source code? * How did you compile your source code? * What compiler did you use? * What platform are you testing on? * Is there anyway you can generate a smaller test case?
Also please don't attach images to emails, use text files wherever possible, and if you need to attach an image please provide a link to it rather than including it in the email.
Don't get too focused on the one instruction Streamline reports as being hot. Streamline is restricted to reporting what it is told by the kernel, and in an out-of-order super-scalar core it doesn't always match what is precisely happening.
In this case my intuition tells me that the problem is the code sequence before the VSUB:
LDR r5, [r4, #0x16c] @ 1 MOVS r3, #0xa4 @ 2 MLA r5, r3, r2, r5 @ 3 VLDR s15, [r5, #0x68] @ 4 VSUB.F32 s15, s15, s16 @ 5
Note the s15 source into insn 5 is loaded in the previous insn. Insn 4's base register is calculated from a Multiply-accumulate inn Insn 3, for which one of the sources is loaded in Insn 1.
So I *think* the 'hotness' is coming from the dependent chain of instructions which when you get to the VSUB the core is waiting to complete before it can do the calculation. But this is a guess - I don't have enough information.
There are instantly many theories I have around why is this the case, but I can't work out what is going on without the information I asked for above.
Thanks,
Matt
linaro-toolchain@lists.linaro.org
-
 Mans Rullgard
Mans Rullgard -
 Matthew Gretton-Dann
Matthew Gretton-Dann -
 Peter Maydell
Peter Maydell -
 Renato Golin
Renato Golin -
 Will Newton
Will Newton -
 YongQin Liu
YongQin Liu